ggGWAS Internals
Sina Rüeger
2019-07-31
gggwas-internals.RmdThis vignette contains some technical aspects about developing the ggGWAS package.
New scale -log10
There are different scales available in ggplot2 that apply a log10 transformation.
-
scale_x_log10andscale_y_log10 -
scale_x_continuous(trans = "log10")andscale_y_continuous(trans = "log10") coord_trans(x = "log10", y = "log10")
They all to slightly different things.
First, there is scale_x_continuous, which simply applies the log10 function to the data. Available transformations include “asn”, “atanh”, “boxcox”, “exp”, “identity”, “log”, “log10”, “log1p”, “log2”, “logit”, “probability”, “probit”, “reciprocal”, “reverse” and “sqrt” (from ?scale_x_continuous)
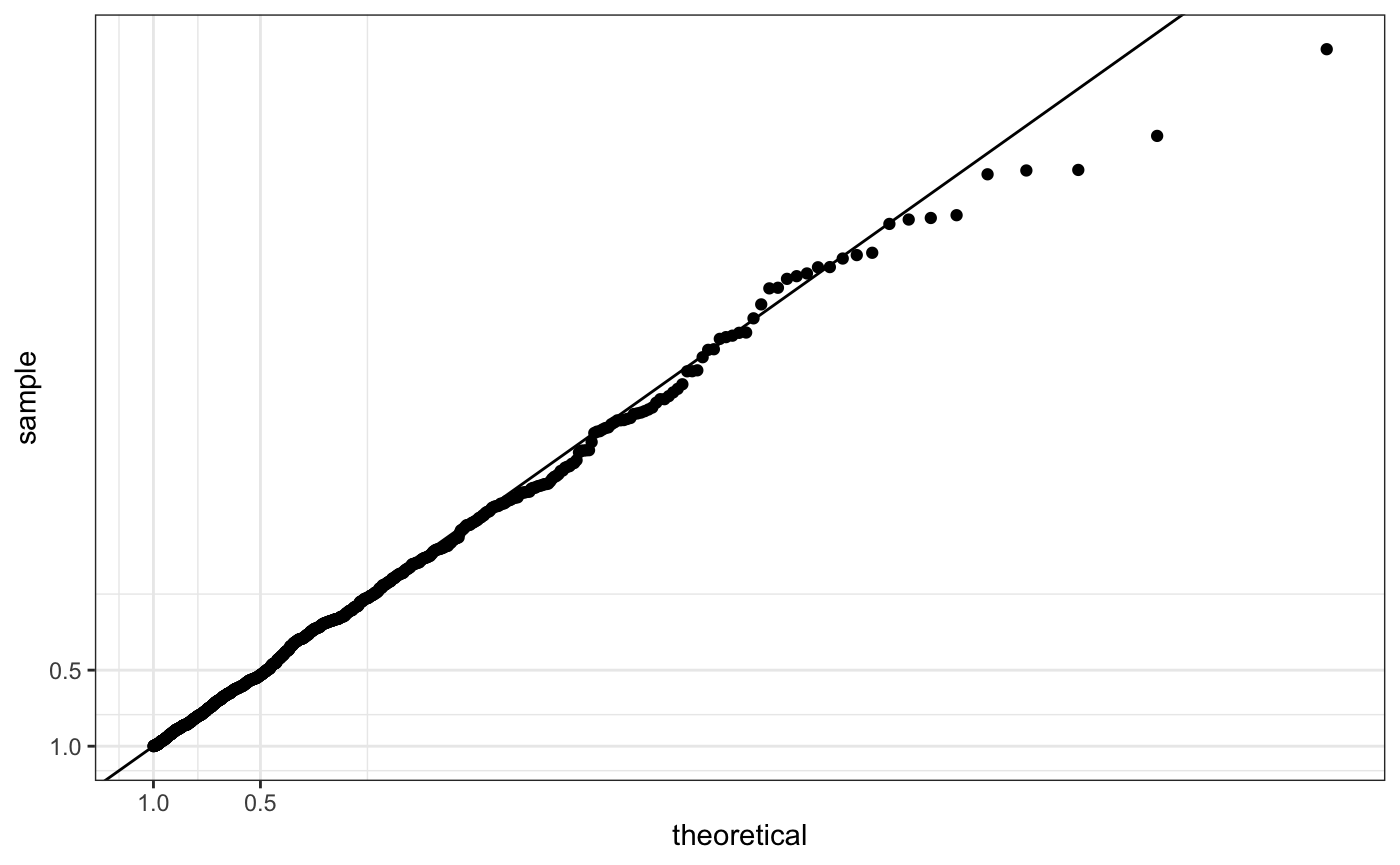
set.seed(3)
df <- data.frame(y = runif(1000))
qp <- ggplot(df, aes(sample = y)) +
stat_qq(distribution = stats::qunif)
qp + scale_x_continuous(trans = "log10") + scale_y_continuous(trans = "log10")
Second, there is scale_{x|y}_log10, which simply applies the log10 function to the data.

Third, there is coord_trans, that takes as input the transformation (which start with scales::*_trans). Note that the grid is different.

For our Q-Q plot we want to create a new transformation that performs a -log10 transformation, which we will call mlog10.
Either we use scale_y_continuous
qp +
scale_y_continuous(trans = "mlog10") +
scale_x_continuous(trans = "mlog10") +
geom_abline(intercept = 0, slope = 1)
or coord_trans (not sure why this won’t work)
R object size, rendering speed and image file size
Three major problems with ggplot2 plots of large datasets are 1) object size, 2) rendering speed and 3) the resulting image file size (e.g. pdf or png).
Passing on a large dataset to ggplot2 will create a large object (because the dataset will actually - in various forms - become part of the object). To manipulate this, would mean to manipulate some core parts of ggplot2.
However, rendering a large object does not necessarily take long. For example, we can avoid plotting each single observation by using hexagons.
A more complex topic is rastering. Rastering actually increases the time to render a plot, but decreases the file output size.
In the following we are going through options to optimise plotting and then measure object size, rendering speed and file output size (as a pdf).
Here are the options:
- Using rastering (
ggrastr:::GeomPointRast) - Using hexagons (
ggplot::geom_hex) - Subsetting data
- Avoiding passing on the full datasets
And here are the the metrics used to measure object size, rendering time and file output size.
print_object_size <- function(x) {
pryr::object_size(x) ## in bytes
## do not use object.size(), as not accurate, or use pryr::compare_size(x)
}
print_rendering_time <- function(x) {
system.time(x)
}
## check out a better benchmarking time post: https://www.alexejgossmann.com/benchmarking_r/
## maybe microbenchmark package?
print_file_size <- function(gg) {
invisible(ggsave("tmp.pdf", gg, width = 4, height = 4))
cat(file.info("tmp.pdf")$size / 1024, " Kb.\n", sep = "")
unlink("tmp.pdf")
}Benchmark: base graphics
Our benchmark is the base plot version from the qqman package:
Raster
The R-package ggrastr does ???. (for the price of longer rendering time).
It creates very light output, but is not necessarily fast.
We can use the rastering functionality as geom in our function.
Hexagons
## Object size
print_object_size(qp_hex)
#> 4.11 MB
## Rendering speed
print_rendering_time(print(qp_hex))
#> user system elapsed
#> 0.367 0.047 1.065
## File output size
print_file_size(qp_hex)
#> 7.183594 Kb.Problem is, that the original dataset is still passed on. This is not a problem in terms of speed, but can be for memory. More about this further down.
Note, that the used hex.function called hexBinSummarise_custom does not have the usual properties, in that it will have the hexagon shape, but not any count legend. Also has a tweaked hexbinheight. If hex.function = hexBinSummarise is used, the plot will have the usual properties.
## old version
ggplot(data = GWAS.utils::giant) + stat_gwas_qq_hex(aes(y = P), hex.function = ggplot2:::hexBinSummarise) 
## new version
ggplot(data = GWAS.utils::giant) + stat_gwas_qq_hex(aes(y = P), hex.function = ggGWAS:::hexBinSummarise) 
Subsetting data
Something very simple is to subset the data, since we are usually not interested in the very high P-values (although, we are at times, when it comes to model sanity checks).
4. Avoiding passing on the full datasets (???)
What makes a ggplot2 object really heavy, is that the dataset is passed on several times into the object.
## data structure
#ggplot_build(qp_hex) %>% str() %>% sapply(dim)
object.size(ggplot_build(qp_hex))
#> 31824 bytes
object.size(ggplot_build(qp_points))
#> 97120 bytes
## grid object
## ggplot_gtable(ggplot_build(qp_hex)) %>% str()
object.size(ggplot_gtable(ggplot_build(qp_points)))
#> 811984 bytes
object.size(ggplot_gtable(ggplot_build(qp_hex)))
#> 776608 bytesNew color palette
See also: https://github.com/mkanai/ggman/blob/master/R/scale-colour-dichromatic.R
New theme
See also: https://github.com/mkanai/ggman/blob/master/R/theme-publication.R